itzulpen-memorien kudeaketa
Gaur egun, itzulpenak egiteko ezinbesteko baliabideak bilakatu zaizkigu OLI (Ordenagailuz Lagundutako Itzulpeneko) tresnak. Ezagunenak TRADOS eta Wordfast dira, besteak beste. Tresna horien bidez itzulitako testuetan, sorburu-hizkuntzako eta xede-hizkuntzako segmentu edo esaldi zehatz baten bikotekidea biltzen dituen unitateari itzulpen-unitate esaten zaio, eta itzulpen-unitate horien bildumak dira itzulpen-memoriak.
Itzulpen-memoriak guztiz baliagarriak dira hizkuntza-teknologietako zenbait arlo lantzeko. UZEIk baliabide propioak garatu ditu aprobetxamendu hori optimizatzeko.
Bestalde, itzulpen-memorien zenbait alderdi eraginkorrak badira ere, honelako arazoak ematen dituzte haien tamaina handitzen denean:
- Informatikoak: erabiltzaile askok memoria bakarrarekin lan egiteko konponbideak garestiak dira oraingoz.
- RAM memoria: memoria handiegiak direnean, tresnak moteldu egiten dira.
- Zabor-pilaketa: zaborra gordetzeak tresnen funtzionamendu optimoa eragozten du.
- Memoriak proposatzen duen itzulpenean testuingurua falta izaten da.
- Informazio pertinentea berreskuratzeko zailtasunak.
UZEIk konponbideak eskaintzen ditu arazo horiek eta gehiago konpontzeko.

AHOLKULARITZA
Itzultzaileei eta itzulpen-zerbitzuei era guztietako zerbitzuak eskaintzen dizkiegu. Esate baterako:
- Lan-antolaketaren aholkularitza
- Itzulpen-memoriak sortzea eta antolatzea
- Itzulpen-memorien datu-basea sortzea
- Glosarioen sorkuntza automatikoa


eLENA
Itzulpen-memoriak kudeatzeko sortutako softwarea da eLENA, itzulpen-corpus eleaniztun eta paraleloak eratzen dituena. Ez du aurrez ezarritako mugarik hizkuntza-kopuruarentzat, eta bezero bakoitzaren beharretara egokitzen da.
Bilaketa dokumentalerako baliabide ahaltsuak dituenez, corpusetako testu elebidunak eta are eleaniztunak kudeatzeko oso erabilgarria da; adibidez, masa handiko itzulpen-dokumentuak eta -memoriak kudeatzeko.
eLENA aplikazioak eskaintzen dituen funtzionalitate nagusien artean, hauek dira azpimarratzekoak: eragile logikoak, hitzen arteko tartea zehazteko eragileak eta karaktere komodinak; corpusa osatzen duten paragrafo-unitate bakoitzaren barruan hitzak edo esaldiak bilatu ahal izatea; eta testu-hitz bakoitza bere testuinguruan kontsulta ahal izatea (jatorrizko dokumentua osorik berreskura daiteke).
eLENAren teknologia dago, adibidez, Gipuzkoako Foru Aldundiaren iMEMORIAK itzulpenen datu-basean eta Eusko Jaurlaritzaren IDABA zerbitzuan.


garbiro
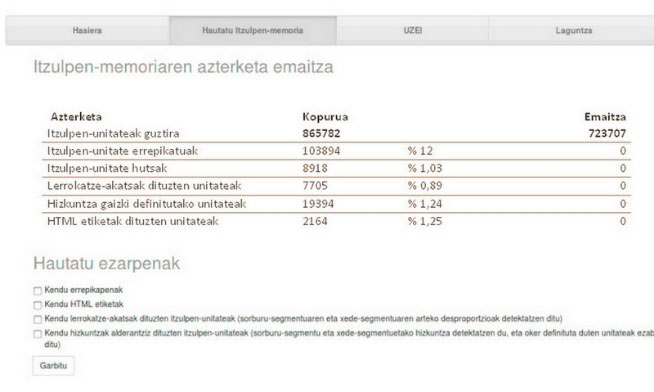
Garbiro: Itzulpen Memorien (IM) errendimendua hobetzeko zerbitzua da.
IMen erabilera intentsiboek ezinbestekoak dituzte mantentze- edo garbitze-lanak, itzulpen-proposamenek erabilgarritasun-maila handiari eusteko. UZEIn itzulpen-memorien alderdi hauek aztertzen dituen zerbitzua eskaintzen dugu:
- Errepikatutako itzulpen-unitateak (=segmentuak)
- Hutsik dauden itzulpen-unitateak
- HTML etiketak (informaziorik ematen ez dutenak)
- Oker lerrokatutako itzulpen-unitateak
- Hizkuntza oker definituta duten itzulpen-unitateak
Esperientziak erakutsi digunez, baliozkoak ez diren itzulpen-unitateak ezabatu ondoren, gure bezeroen IMen errendimendua nabarmen hobetzea lortu dugu Ordenagailuz Lagundutako Itzulpenerako tresnen erabileran.
Irudia: Garbiro erabiliz itzulpen-memoria batean garbitze-lanak egitearen emaitza.
itxek
Itzulpenen egokitasuna egiaztatzeko sistema
Euskarara itzultzen diren testuen kalitatea eta kontsistentzia bermatzeko tresna da iTXEK, itzulpen-prozesua optimizatuz prozesua bera errentagarriagoa bilakatzen duena.
Itzulpen-memorietan, iturburu-hizkuntzako segmentuen eta xede-hizkuntzako segmentuen artean sortzen diren inkontsistentziak detektatzen ditu, zuzentzeko bidea emanez. Segmentazioaren eta puntuazioaren egiaztapena egiten du, lehenik.

Alderdi lexikoan, berriz, horrelako testu paralelo elebidunetan erabilitako lexiko orokorra eta terminologia lematizatu eta erabiltzaileak aldez aurretik aukeratutako hiztegi batekin alderatuz egiaztatzen ditu. Era berean, entitateak detektatzen ditu, eta itzulpen-unitate bateko bi segmentuetan entitateen baliokideak egiaztatzeko eta are babesteko aukera ematen du.
Itzulpengintzan erabiltzeko garatu den arren, testu paraleloetan lexikoaren erabilera zuzena egiaztatzeko erabil daiteke, esate baterako, lege-testu elebidunetan (aldizkari ofizialetako testuak, Zigor Kodea…).
Horrela, terminologoak egiazta dezake hiztegigintzarako corpuseko testu paraleloetan zein termino edo termino-hautagai erabili diren.
iTXEK proiektua Eusko Jaurlaritzaren Saiotek 2010 deialdian aurkeztu zuen UZEIk.