translation memory management
CAT tools (Computer Assisted Tools) have become indispensable resources for translating. Among them the most well-known are TRADOS and Wordfast, among others. In a text translated with the aid of CAT tools, the pair made up of the source language segment and the target language segment is called a translation unit; translation memories are collections of these translation units.
Translation memories are useful for developing a variety of spheres of language technologies. UZEI has developed its own resources to optimise their performance.
On the other hand, although certain aspects of translation memories are efficient, as they grow in size, they may generate problems like the following:
- Computer problems: solutions enabling simultaneous use of the same memory by a large number of users are still extremely expensive.
- RAM memory: large memories slow down the devices in which they are used.
- Accumulation of useless information: storing useless information (junk information) hinders the optimum working of the tools.
- Translations managed by translation memories are usually free of context.
- Difficulties in retrieving pertinent information.
UZEI places solutions for these and other problems at their clients’ disposal.

COUNSELING
A large array of services is at the disposal of translators and translation services, such as:
- Advisory services in matters relating to task organisation
- Creation and organisation of translation memories
- Creation of translation memory databases
- Automatic generation of glossaries


eLENA
eLENA is software designed for managing translation memories, which generates a corpus of multilingual and parallel translations. There are no restrictions as regards languages, and it adapts to suit the specific needs of each client.
Thanks to its powerful resources for seeking documents it is particularly useful for managing bilingual and even multilingual text corpora; e.g. for managing large text masses in translation documents and memories.
Of the main features of the eLENA application, the following stand out: the use of logical operators, operators for determining the distance between words and wildcard characters; the chance to do word and phrase searches in paragraphs making up the corpus; and the chance to consult each word of the text in its context, given that the whole original document can be retrieved.
eLENA technology is used, e.g. in the Gipuzkoa Regional Government’s translation database (iMEMORIAK) as well as in the Basque Government’s IDABA service.


garbiro
Garbiro: a resource for improving translation memory (TM) performance.
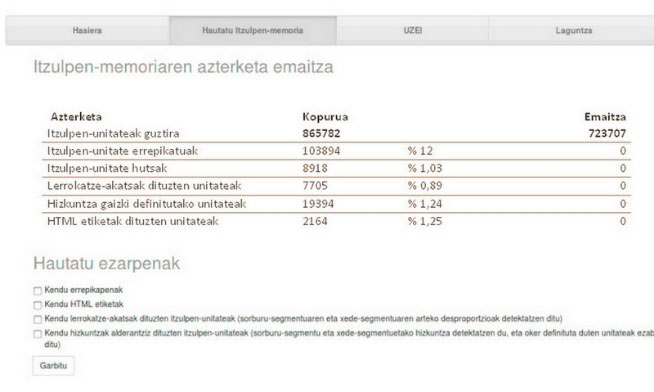
Intensive use of Translation Memories requires maintenance or debugging, so that translation proposals maintain high usability. UZEI offers a service that analyzes the following aspects of translation memories:
- Repeated translation units (=segments).
- Empty translation units
- HTML tags (that do not provide any information)
- Misaligned translation units
- Translation units with incorrectly defined languages
Based on our experience with our clients’ translation memories, debugging of invalid translation units web results in a considerable performance increase in the use of TMs with CAT tools.
Image: Result of a translation memory processed by Garbiro.
itxek
A system for guaranteeing the consistency of translations
iTXEK is a tool for guaranteeing the quality and consistency of the text translated into Basque, while optimizing the translation process and making it more cost effective.
In translation memories, it detects inconsistencies between source and target language segments, giving the user the option to correct them. As a first step, it checks both the segmentation and the punctuation.

In the field of lexicon, iTXEK lemmatizes the general and specialized lexicon of parallel texts and checks it by comparing it with a dictionary previously defined by the user. Similarly, it detects named entities in both segments of a translation unit, and offers the option of checking and even sanitizing them.
Although it has been developed to be used in the field of translation, it can be used to check the correct use of the lexicon in parallel texts; for example, in parallel legal texts such as official gazettes, versions of laws, etc.
The iTXEK project was presented at the Basque Government’s Saiotek 2010 call for proposals.